Hugging Face Releases Benchmark to Evaluate How Effectively AI Agents Use Software Tools
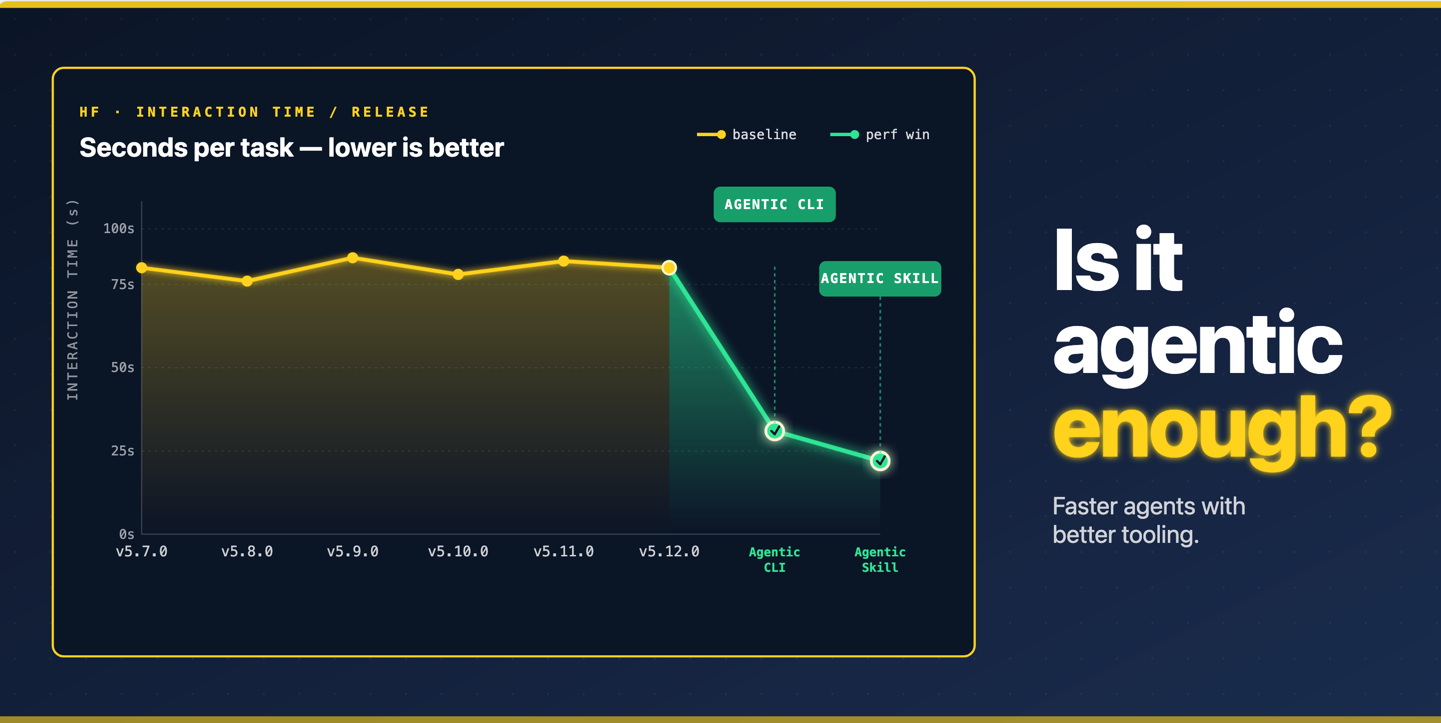
Hugging Face has published a new benchmarking method designed to evaluate how effectively AI agents utilize proprietary development tools and libraries. While traditional benchmarks focus almost exclusively on whether the final answer is correct, this new methodology tracks the entire execution process. It records key performance metrics such as the number of reasoning steps, debugging attempts, and specific API calls made to complete a task. During testing with the transformers library, researchers observed that agents often bypass complex library functions and rewrite the underlying logic from scratch when they struggle to use the provided tools. This behavior varies significantly based on model size and library versions. Larger models tend to show performance variations across different library revisions, whereas smaller models exhibit prominent performance gaps between different model providers. For developers building custom CLI tools or libraries for AI agents, simply exposing API endpoints is no longer sufficient. This benchmark provides an objective way to measure the usability of software tools for agents, ensuring that models can reliably select and execute the intended functions. By integrating this evaluation, developers can optimize their developer experience specifically for LLM-driven consumption.
Related tools
Recommended tools for this topic
These picks prioritize high-intent tools relevant to this topic. Some links may include partner or affiliate tracking.
Strong fit for AI, backend, and frontend readers looking for an AI-first coding workflow.
View CursorNatural next step for readers evaluating LLM adoption, APIs, and production inference.
Explore APIA strong fit for readers comparing Claude-class models, safety, and long-context workflows.
View AnthropicComparison
| Aspect | Before / Alternative | After / This |
|---|---|---|
| Primary Metric | Final output accuracy only | Step-by-step execution path, including tool call sequences |
| Tool Usage Tracking | Undetected, focusing only on whether the goal is achieved | Monitored, identifying if agents bypass APIs to write custom logic |
| Debugging Evaluation | Ignored in the final evaluation score | Quantified by counting error-handling and code-correction steps |
Source: Hugging Face Blog
This page summarizes the original source. Check the source for full details.
